H16
-29/8/2025- Internet est en train de changer, et de changer plus vite que vous ne pouvez l’imaginer : d’un côté, jamais produire du contenu n’a été aussi facile mais de l’autre, jamais le contenu réellement humain et original n’a été aussi rare…

La tendance est évidente pour qui regarde avec attention ce qui se passe depuis quelques années avec, notamment, l’arrivée de l’intelligence artificielle : on assiste actuellement à une déferlante de contenus, ces derniers étant de plus en plus créés par des moteurs d’intelligence artificielle. Que ce soit pour l’image, la musique, la vidéo, le texte, la production des moteurs d’intelligence artificielle s’étend tous les jours un peu plus et ce d’autant plus que ces contenus sont, à leur tour, utilisés par les moteurs pour nourrir leurs bases d’apprentissage.
En effet, à mesure qu’enflent les capacités des moteurs grossissent aussi leurs besoins de données pour s’entraîner : dans ce cadre, la production de données « synthétiques » devient nécessaire. Or, au-delà même de la question de savoir si ces données synthétiques permettent réellement une amélioration des apprentissages, un autre phénomène est en train d’émerger.
Sur les deux dernières décennies, Google et Meta ont dominé le web en échangeant gratuitement leurs services contre des publicités. Dans ce cadre, les utilisateurs obtenaient du contenu, les créateurs de ce contenu pouvaient obtenir du trafic de la part de ces deux firmes, et les annonceurs, de leur côté, obtenaient des audiences ciblées et détaillées sur lesquelles pousser leurs messages construits sur mesure.
L’essor de l’intelligence artificielle a bouleversé ce triptyque : le nombre de créateurs a explosé au point de rattraper celui des utilisateurs, une partie grandissante des utilisateurs est maintenant représentée par des bots qui viennent extraire des contenus nécessaire pour les inférences des moteurs, et dans les cas les plus extrêmes, les publicitaires se retrouvent obligés d’utiliser des bots pour… vendre à des bots, ce qui n’est guère efficace commercialement parlant.
Cette situation est en train de pousser l’internet vers une « fracturation par facturation » : l’accès gratuit n’est plus possible par défaut.
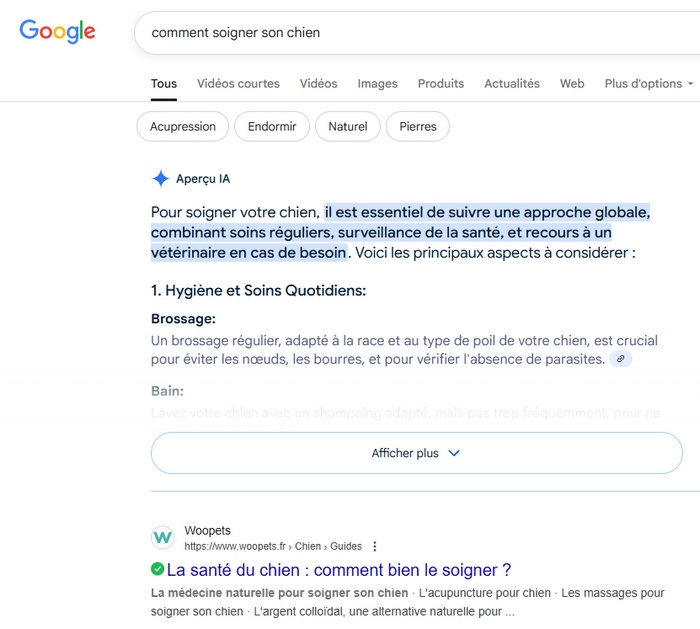
En 2022, avec l’arrivée de ChatGPT, les utilisateurs ont modifié de façon brutale leurs comportements : au lieu d’utiliser Google pour chercher internet, ils ont commencé à utiliser les explications fournies par l’IA, privant de fait les éditeurs du trafic habituel alors même que leur contenu sert de base aux réponses fournies par les modèles. À présent, la recherche assistée par l’IA de Google, qui apparaît automatiquement sur certains types de questions, réduit de plus de la moitié les clics sur les liens de sites web. Parallèlement, les recettes publicitaires du géant informatique ont pourtant augmenté de 10% en 2024 (265 milliards de dollars au total).
Les éditeurs et producteurs de contenus, comprenant la situation, multiplient donc actuellement les exigences avant connexion à leurs sites : « murs de paiement » pour imposer un revenu d’abonnement, Captchas et, pour certains sites (Reddit, StackOverflow par exemple), exigence d’un paiement pour les robots qui viennent pomper les données, selon le modèle « Pay To Crawl » mis en place par Cloudflare.
Autrement dit, le web tel qu’il existait jusqu’à présent est rapidement en train de se scinder en deux communautés pour les différents types d’utilisateurs : le web gratuit mais sans barrières, dont une partie croissante est composée de contenu synthétique, et qui est systématiquement utilisée par les moteurs, et un autre web plus restreint, composé des services exclusivement destinés à des humains (newsletters, groupes Discord, forums niche), géré et entretenu par des humains et seulement des humains.
Petit-à-petit apparaissent les deux couches de ce nouveau web, l’une fournie et entretenue par l’IA, alimentée par la publicité et optimisée pour fournir des réponses rapides, instantanées, pendant que l’autre est réservée – sur base d’abonnement ou de contraintes spécifiques – à des humains.
Si l’on projette cette tendance à plus long terme, avec d’un côté les données synthétiques dont le nombre explose et de l’autre les données humaines qui sont de moins en moins accessibles, on comprend que le ratio des données humaines sur les données totales va donc décroître. Inévitablement, les données générées par l’homme vont donc se raréfier en rapport, gagnant en valeur et ce d’autant plus que les données de l’internet sont toujours plus contaminées par les résultats de l’intelligence artificielle. Il n’est pas déraisonnable d’imaginer que, dans un futur proche, le paiement à la recherche ou le paiement au « scrapping » de données remplaceront l’octroi de licences sur le contenu ou les droits d’auteur.

À la longue, on peut même envisager que le paiement de ces parcours, qui sont plus faciles à gérer et rapidement plus rentables que la gestion des droits d’auteur pour les créateurs de contenus et les éditeurs, fasse progressivement disparaître les droits d’auteurs traditionnels, de la même façon que la disparition des frictions dans l’accès à l’information a fait s’écrouler les prix de beaucoup de services (les agences de voyage, de taxi, d’immobilier en savent quelque chose). De ce point de vue, le paiement au parcours tel qu’il est expliqué ici trouve un bon équilibre : d’un côté les humains peuvent circuler librement, et de l’autre les robots payent à l’entrée de chacun des sites.
Au début d’internet, seuls les spécialistes et les passionnés se connectaient entre eux. L’arrivée des firmes commerciales, le développement des communications bien au-delà de ces utilisateurs spécifiques a permis au plus grand nombre d’accéder au partage d’information, au détriment évident de la qualité des contenus.
Cependant, l’étape suivante dont on observe la naissance pourrait renvoyer le balancier dans l’autre sens, forçant le retour ou la création de communautés plus spécialisées. Alternativement, on peut imaginer la dystopie dans laquelle les humains, noyés dans les contenus synthétiques, finissent par perdre complètement pied et ne plus pouvoir former ces communautés autrement que dans le monde réel, loin du monde numérique ainsi réservé aux bots.
Mais quoi qu’il en soit, rien ne nous aura préparé à ce qui va arriver dans les prochaines années.