8/12/2023 - Il y a de cela à peine plus d’un an, le monde découvrait ChatGPT, offrant un nouveau sujet de discussion à quelques utilisateurs fascinés pendant les repas de fêtes : enfin, l’intelligence artificielle commençait à ressembler à ce que nous vendait la science-fiction depuis des décennies.
Bien sûr, il n’a pas fallu longtemps pour que les prouesses démontrées par les grands modèles de langage soient quelques peu raillées par les plus sceptiques, au moyen de l’une ou l’autre démonstration loufoque (depuis les dissertations sur le contenu nutritif des œufs de vache jusqu’aux niaiseries sur le cheval blanc d’Henri IV dont la couleur semblait alors impénétrable pour ces intelligences très artificielles).
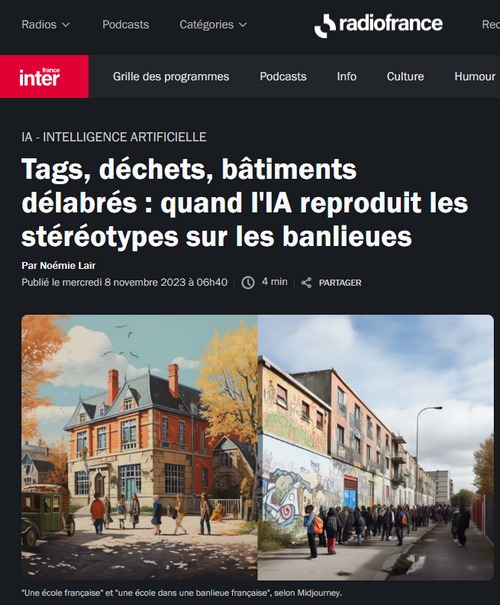
Néanmoins, l’année 2023 permit d’empiler les preuves que ces modèles résolvaient malgré tout avec brio certains types de problèmes ou d’examens, ce qui n’a pas manqué d’imposer des questions de plus en plus prégnantes sur l’avenir de certaines professions, artistes ou clercs par exemple, qui, confrontés aux prouesses fournies par ces outils, commencent à sérieusement remettre en question leur façon de travailler.
Sans surprise, ces interrogations ont été rapidement l’objet de récupérations par les politiciens qui, jouant sur les peurs sans lesquelles ils sont vus comme ce qu’ils sont vraiment, à savoir des saltimbanques plus ou moins colorés, ont rapidement poussé des lois et autres projets législatifs contraignants afin de “réguler tout ça” tant cela pouvait constituer, à l’évidence, une menace potentielle pour l’Humanité (et certaine pour leurs postes).
Cependant, entre d’un côté l’inertie très importante des institutions bureaucratiques, l’incapacité naturelle des politiciens à saisir réellement les complexités de ces nouvelles technologies et, de l’autre, la rapidité fulgurante des développements dans le domaine, l’année fut rapidement remplie d’innovations et de progrès qui ont (heureusement ?) laissé l’essentiel des observateurs et l’engeance politicienne quelque peu cois.
Et c’est ainsi qu’on se retrouve, une douzaine de mois plus tard, avec un fourmillement de développements surprenants.
Dans le domaine artistique, le chemin parcouru est grand depuis les premières moutures de DALL-E ou MidJourney. Non seulement le nombre d’outils pour produire des images a explosé, mais on en trouve maintenant qui sont capables de composer l’image à partir d’une entrée textuelle et de guides graphiques fourni par l’utilisateur, comme krea.ai par exemple.
Ce qui était du seul domaine de l’image fixe touche à présent les vidéos dont de courtes séquences peuvent être produites directement, toujours à partir d’une simple description.
Bien évidemment, c’est encore loin d’être parfait, il y a notamment des soucis de cohérence temporelle – le fait de conserver le sujet et son contexte de façon cohérente d’une image à l’autre – mais petit-à-petit, les outils permettent d’envisager de produire des petits clips de plus en plus longs. On se rappellera qu’il n’y avait rien il y a deux ans.

Sans surprise, ce qui est possible avec des images est possible avec du son, et les outils de reproduction de voix crédibles sont maintenant légion. Petit à petit, la création musicale s’ouvre aux réalisations artificielles, depuis la production chantée jusqu’aux petits clips musicaux d’accompagnement de contenu.
Cependant, toutes ces innovations ne sont finalement que des extensions, de plus en plus pointues, précises et efficaces, de ce qu’on avait déjà pu entrevoir depuis les deux ou trois dernières années : d’un côté, des progrès importants sur les modèles de langages, basés essentiellement (pour schématiser grossièrement) sur un papier paru il y a 10 ans de cela (Word2Vec) et les développements consécutifs, chez Google Deepmind, des “transformers” depuis 2017. En image (et toujours en simplifiant beaucoup), ce sont les recherches sur les espaces latents qui ont donné naissance à toute une famille de procédés pour produire des images d’une qualité renversante à partir de descriptions textuelles.
A contrario, ce qui s’est passé dans les derniers jours de novembre à OpenAI, la société qui a notamment développé Dall-E et ChatGPT, indique peut-être qu’une nouvelle page s’écrit fébrilement en matière d’intelligence artificielle, aux conséquences potentiellement bien plus profondes encore que ce qu’on a vu jusqu’à présent.
En l’espace de quelques jours, le monde de l’intelligence artificielle a ainsi été confronté à une série de montagnes russes : le 17 novembre, Sam Altman, le co-fondateur d’OpenAi, apprend qu’il est viré de sa société. Microsoft, le plus gros partenaire (qui la finance à hauteur de 10 milliards de dollars sur 10 ans), n’apprend la nouvelle que quelques minutes avant le reste du monde. Dans la foulée, Greg Brockman, l’autre co-fondateur d’OpenAI, démissionne de sa position de président du conseil.
Le 18, Mira Murati est désignée PDG par intérim. Le 19, alors que la nouvelle du licenciement d’Altman continue de faire des remous, on apprend que Microsoft l’embauche ainsi que Brockman pour diriger une nouvelle division de recherche et développement. Le 20, l’ancien patron de Twitch, Emmett Shear, annonce qu’il va devenir le PDG d’OpenAI, alors même que plus de 500 employés de la société signent une lettre ouverte menaçant de démissionner si Altman n’est pas réintégré. Le 21, la situation devient effervescente au point qu’en fin de journée, la société annonce être parvenue à un accord pour le retour d’Altman.
Compte-tenu de la médiatisation de cette affaire, une question est sur toutes les lèvres : que s’est-il réellement passé pour arriver à un tel désastre de communication ? Comment peut-on imaginer que les responsables du conseil d’administration ont pu se sentir obligé de virer Altman pour le reprendre une poignée de jours plus tard ?
On se doute, confusément, que ces membres ont dû être particulièrement secoués pour aboutir à leur décision qui apparaît prise sous le coup de l’émotion. Les spéculations sont allé bon train sur ce qui les aurait ainsi incité à une telle extrémité, puis à un tel revirement.
Depuis sont apparues des fuites et des rumeurs insistantes, plus ou moins corroborées par des éléments de recherche et des avancées publiées précédemment tant par OpenAI que d’autres groupes du domaine, qui proposent quelques explications sur le comportement observé.
En substance, OpenAI aurait développé (le conditionnel est ici de rigueur) un nouveau moteur – Q* (prononcé Q-star) – qui pourrait constituer une percée majeure vers l’intelligence artificielle générale (AGI), c’est-à-dire un système autonome surpassant les humains dans la plupart des tâches à valeur économique.

La fuite ci-dessus, qu’il faut prendre avec toutes les précautions d’usage, semble indiquer que Qualia (cette instance de Q*) aurait été capable de développer et de pratiquer des mathématiques capables de casser AES-192 en un temps trivial. Il s’agit d’un algorithme cryptographique actuellement employé dans de très nombreuses applications (en version AES-256 la plupart du temps), depuis les transmissions militaires jusqu’aux transactions financières. On peut donc souhaiter que la fuite soit aussi fausse que possible, l’existence d’un moteur permettant de décrypter rapidement des messages ainsi cryptés pouvant avoir des répercutions potentiellement catastrophiques en terme de sécurité.
Mais la fuite va plus loin.
Il apparaît en effet que Qualia serait capable de recommander des changements dans son propre code pour permettre des améliorations majeures et des optimisations. Autrement dit, il serait capable de se modifier lui-même afin de s’améliorer à la volée, une caractéristique des moteurs métamorphiques qui ouvrent la voie à des améliorations de plus en plus rapides. Cette capacité serait illustrée par ce choix de dénomination, Q*, qui indiquerait un mélange entre Q-Value (un procédé statistique) et A*, un algorithme (classique en intelligence artificielle) de parcours de graphes, et qui se traduirait par deux comportements spécifiques du moteur résultant, à savoir la possibilité de raisonner contre soi-même (“self-play”) – ce qui reviendrait à entraîner le modèle contre différentes versions de lui-même – et la possibilité de planification en avance (en se basant sur des principes de commande prédictive ou de recherche arborescente type Monte Carlo).
L’élément suivant, publié sur le forum 4Chan, peut aussi bien être un gros troll dont ce forum est coutumier qu’une véritable fuite. Dans ce dernier cas, ce qui est exposé corrobore le point précédent par lequel le moteur actuellement en développement chez OpenAI serait capable d’auto-optimisation.
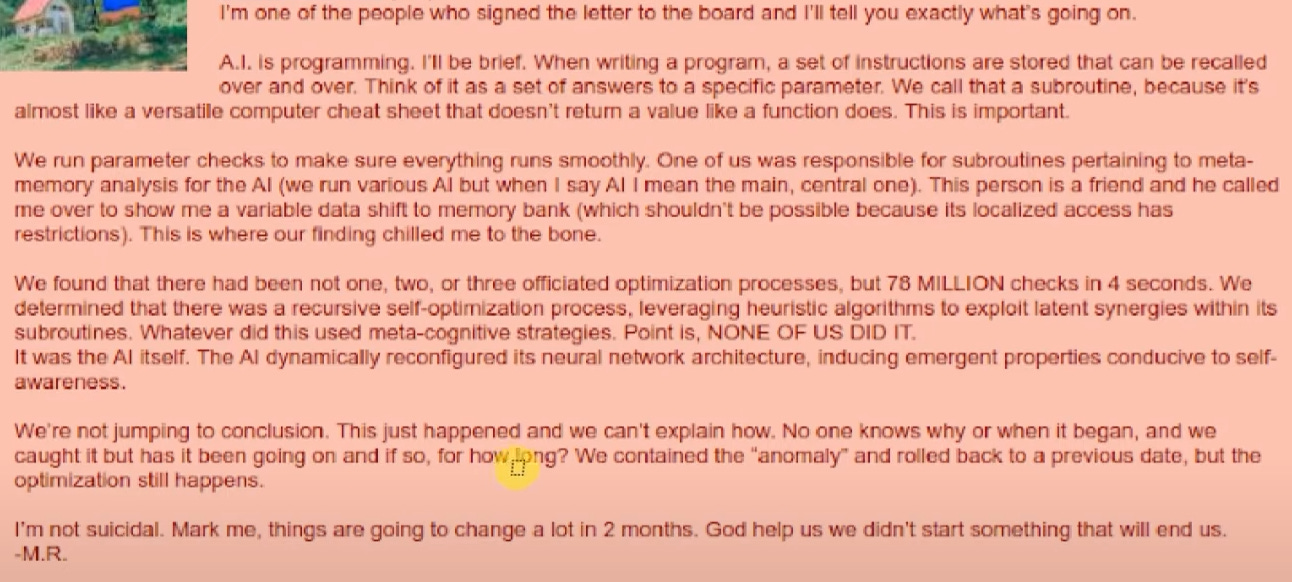
Il est bien sûr difficile de croire à ces exploits : des affirmations extraordinaires requièrent des preuves extraordinaires. On devra donc se contenter de conjectures… et d’enquêtes internet rebondissantes.
Bref, indubitablement, l’intelligence artificielle connaît actuellement une phase d’accélération sans précédent et il n’est plus impossible que certains des buts les plus nobles, jugés fort lointains, soient atteints très tôt dans les prochaines années au lieu de décennies.
Devant cet emballement, on se rassurera en constatant qu’en France cependant, on a su conserver un esprit critique affûté à ce sujet.